Keyword System Settings
![]() Reference Contents > Advanced Functions > Keyword System Settings
Reference Contents > Advanced Functions > Keyword System Settings
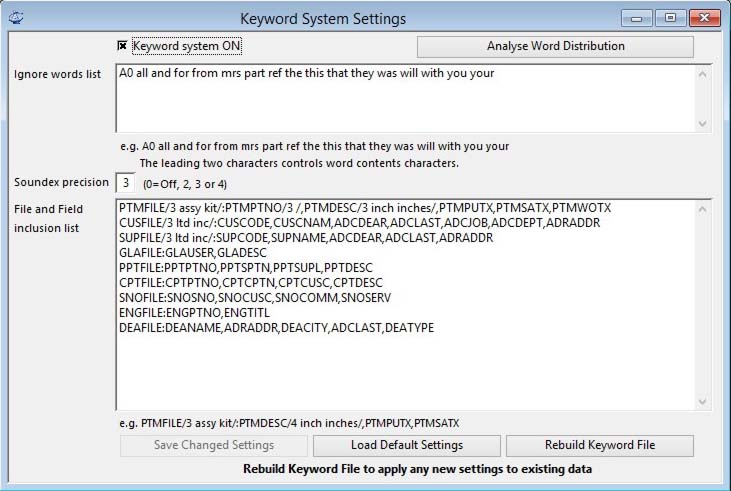
All controls for the Keyword System are located through File — Advanced — Keyword System Settings menu route. For details on Keyword Search operation see the Keyword Search Results topic.
With a new data file, settings will be Off and blank. You can use the Load Default Settings button to set up a standard set of controls and then modify them. When you are content, click on the Save Changed Settings button.
Keyword system ON
This checkbox simply turns the system On and Off. With the Keyword system turned on:
1. You will attach automatically to the .KWD datafile associated with your normal datafile (see later). If there is no .KWD data file, one will be automatically created. (The name of the datafile will be the same as your current datafile with “.KWD” appended to it or replacing the .DF1 suffix.)
![]() NOTE: You will receive a warning if a new .KWD file can not be created. There can be a number of standard operating system reasons for this, e.g. protected disk, etc.. For Macintosh systems the normal datafile name may be too long to append .KWD to it.
NOTE: You will receive a warning if a new .KWD file can not be created. There can be a number of standard operating system reasons for this, e.g. protected disk, etc.. For Macintosh systems the normal datafile name may be too long to append .KWD to it.
2. The *, ? and ?? syntax on data record finds will function and will be as successful as far as the word content of the keyword file permits.
3. Depending on other settings below, when master records are added (e.g. Customers) or deleted, computed keywords will be added to or deleted from the keyword datafile.
Turning the checkbox off simply disconnects you from the .KWD datafile and disables the normal On functionality. It does not destroy the .KWD keyword datafile.
![]() WARNING: If you turn off the Keyword system, add or delete a number of master records, then reset it On again you will subsequently have an incomplete keyword file.
WARNING: If you turn off the Keyword system, add or delete a number of master records, then reset it On again you will subsequently have an incomplete keyword file.
Soundex Precision
This controls access to and the generation of Soundex codes. Set this to 0 to turn the Soundex option off. See later for a full discussion on Soundex.
Ignore Words List
This provides a control for the entire Keyword system in two areas:
Firstly you can set the character set that determines a word. Words are extracted based on the string of characters that make them up. They can be alpha-only or alpha-numeric. The first two characters of this control field determine the range of character that are permitted to make up a word. There are three alternatives:
|
Entry |
Type |
Example |
|---|---|---|
|
AA |
Alpha-only (technically all Unicode characters other than numbers and proscribed ones) |
PART, PARTS, PARTICULAR etc. |
|
A0 |
Alpha-numeric |
PART, PART278, PART00000, etc. |
|
00 |
Numeric-alpha |
123PART2, 678595, PARTS, etc. |
In all respects words are de-limited by spaces or any punctuation characters. However, using this code you can make words Alpha-numeric or Numeric-alpha.
Following the word constitution characters you can list all those words that should be excluded from the Keyword file contents, separating them with a space character. Simply type in the words that are common and of no use in any keyword search. These will then be ignored when creating the keywords.
File/Field inclusion list
This is a single text field that enables you to set up from where the system collects the words to make up the keyword file. The settings control must be set up with a line for each file, terminated with a return character. The following files are supported:
|
Filename |
Contents |
|---|---|
|
CPTFILE |
Customer Parts |
|
CUSFILE (plus fields from ADRFILE and ADCFILE) |
Customers with all their addresses and contacts |
|
DEAFILE (plus fields from ADRFILE and ADCFILE) |
Marketing Businesses with all their addresses and contacts |
|
ENGFILE |
Engineering Data |
|
GLAFILE |
General Ledger Accounts |
|
PPTFILE |
Purchase Parts |
|
PTMFILE |
Parts Master |
|
SNOFILE |
Serial Numbered Products |
|
SUPFILE (plus fields from ADRFILE and ADCFILE) |
Suppliers with all their addresses and contacts |
Any other files you list are ignored.
For each of the files listed you should list the fields the contents of which will be used to extract keywords. You terminate the file name with a : (colon) character then the fields with a , (comma) character. So for the Parts Master you could enter:
PTMFILE:PTMDESC,PTMNOTE
This would extract words in the Parts Master file from text contained in fields PTMDESC (Part description) and PTMNOTE (Engineering notes).
You can further control the exclusion of words and the minimum length of words. This is done by delimiting these further controls using two / characters after the filename or field name. The first character within the control, if a number, determines the minimum word length, thereafter exclusion words can be listed. For example:
PTMFILE/3 assy kit/:PTMPTNO/4 /,PTMDESC/4 inch inches/,PTMPUTX,PTMSATX,PTMWOTX
This breaks down as:
|
Element |
Effect |
|---|---|
|
PTMFILE |
Parts Master file records included in keywords |
|
/3 |
For all PTMFILE fields the minimum word length is 3 characters |
|
assy kit/: |
For all PTMFILE fields ignore the words “assy” and “kit” |
|
PTMPTNO |
Include text contained in the field PTMPTNO – Part Number |
|
/4 /, |
Part number field words must be a minimum of 4 characters |
|
PTMDESC |
Include text contained in the field PTMDESC – Part Description |
|
/4 |
For the PTMDESC field the minimum word length is 4 characters |
|
inch inches/, |
For the PTMDESC field ignore the words “inch” and “inches” |
|
PTMPUTX, |
Include text contained in the field PTMPUTX – Purchase individual text (no other controls) |
|
PTMSATX, |
Include text contained in the field PTMSATX – Sales individual text (no other controls) |
|
PTMWOTX, |
Include text contained in the field PTMWOTX – Works individual text (no other controls) |
Note that the field names should all be in upper case, whereas exclusion words are case-insensitive.
Note also that any changes you make to the settings only apply from that point onwards. To reset the existing keyword file, you should click on the Rebuild Keyword File button.
Rebuild Keyword File
This operates a process that completely replaces the existing .KWD file with a new one built using current settings. It may take a good deal of time depending on the extent of files and fields included and the contents of these fields.
Take great care in choosing the fields to be included. Do not gratuitously include fields containing significant text lengths as this will unnecessarily clog up the system.
![]() WARNING: When attached to the datafile via the Omnis Data Bridge a Keyword Data File can only be re-built from a newly created data file. You can only do this by creating a new datafile (File — Advanced — Create New Datafile), naming and filing it correctly on the server.
WARNING: When attached to the datafile via the Omnis Data Bridge a Keyword Data File can only be re-built from a newly created data file. You can only do this by creating a new datafile (File — Advanced — Create New Datafile), naming and filing it correctly on the server.
Unicode (from V4.0000)
From Caliach Vision V4.0000 the character system known as Unicode is fully supported. This permits any international script character to coexist with any other. Prior to this Keywords could only include simple Latin letters. Under Unicode the letter “a” can coexist with East-Asian character “㌀“. The Unicode system uniquely defines characters, punctuation and control characters in a up to 4 bytes, rather than the the original ASCII which only uses 1 byte. This presents a problem for Keyword search in that the separation of words can be by many different ranges of characters depending on the language (in fact some South East Asian languages do not use word separators at all, such as Thai, see below). Unicode characters are typically represented in the form of U+3300, where 3300 is the hexadecimal value for the character (13056 in decimal). For more information on the Unicode system see http://en.wikipedia.org/wiki/Unicode.
![]() TIP: For languages such as Thai and Lao which do not visually separate words, the entire text becomes one word in the Keyword system. You can though use the special Zero Width Space (ZWSP) character in the text. This character is U+h200B (you can find it in Windows Character Map utility for Arial font, Advanced view and Go to Unicode 200B). On the Mac use Option-200B. This character, invisible when viewed, is seen by the Keyword system which breaks the text at that point.
TIP: For languages such as Thai and Lao which do not visually separate words, the entire text becomes one word in the Keyword system. You can though use the special Zero Width Space (ZWSP) character in the text. This character is U+h200B (you can find it in Windows Character Map utility for Arial font, Advanced view and Go to Unicode 200B). On the Mac use Option-200B. This character, invisible when viewed, is seen by the Keyword system which breaks the text at that point.
To handle multi-lingual Unicode word separation the Keyword system uses a list of ranges of non-character Unicode values that will lead to word separation. In normal English this would include spaces and punctuation marks. The default set of non-character values is held in string s5250 and consists of a number or pairs of hexadecimal values separated by ; (colons), the two values in the pair are separated by a comma, each value in the range 0 through 10FFFF, like this:
0000,002F;003A,0040;005B,0060;007B,009F;...
This leading range covers typical European languages. Ranges are inclusive.
![]() CUSTOM CAPABILITY: You can change this string to exempt special characters or, add to the exclusions by entering your own list of pairs to string s5251, which is reserved for this purpose. The first, or only, value must be hexadecimal in the right range. If you have only one value that single value will consist the range. If the second value is less than the first, they will be reversed.
CUSTOM CAPABILITY: You can change this string to exempt special characters or, add to the exclusions by entering your own list of pairs to string s5251, which is reserved for this purpose. The first, or only, value must be hexadecimal in the right range. If you have only one value that single value will consist the range. If the second value is less than the first, they will be reversed.
Character Normalisation
Unicode allows a significant number of characters to be represented by more than one sequence of code points. For example, consider the letter E with circumflex and dot below, a character that occurs in Vietnamese (Ệ). This character has five possible representations in Unicode:
- U+0045 Latin capital letter E
U+0302 combining circumflex accent
U+0323 combining dot below - U+0045 Latin capital letter E
U+0323 combining dot below
U+0302 combining circumflex accent - U+00CA Latin capital letter E with circumflex
U+0323 combining dot below - U+1EB8 Latin capital letter E with dot
U+0302 combining circumflex accent - U+1EC6 Latin capital letter E with circumflex and dot below
A character represented by more than one individual character is referred to as a composite
character. A character represented by a single character is referred to as a pre-composed
character.
As far as the end-user is concerned any of the above constructions of the visual character will look the same. But for a database system they will be seen quite differently. The construction will effect sorting, comparisons and will consume different amounts of space. In 1 above what appears as one character to the user will consume 3 characters in the field, when stored.
There is a process that deals with this known as canonicalization, which basically means converting composite characters into their pre-composed form or if there is not one available into a standard composite form that is consistent and therefore results of comparisons will be what the user expects. The process typically breaks down composite characters into their elements (canonical de-composition) and then re-combines them into a normalised form (canonical composition). Within Caliach Vision, this is automatically performed for all fields that are indexed, as the user enters their value (a Customer Name, for example). As Keyword search typically extracts words from non-indexed fields, the Keyword system performs this normalisation before it extracts the words.
![]() TIP: Pasting from the clipboard into a field always normalises the incoming text, so one trick to force normalisation is to select all the text entered into a field, copy and then paste.
TIP: Pasting from the clipboard into a field always normalises the incoming text, so one trick to force normalisation is to select all the text entered into a field, copy and then paste.
![]() TIP: You can perform a wholesale normalisation of all non-indexed character field data in the File — Advanced — Re-unite Missing Relatives using the nfc() Normalise function.
TIP: You can perform a wholesale normalisation of all non-indexed character field data in the File — Advanced — Re-unite Missing Relatives using the nfc() Normalise function.
Analysis of Word Distribution
There is a tool that enables you to analyse the distribution of the Keywords stored. This may be useful to optimise the system by eliminating common words which are no use in data retrieval within the system. Click on the Analysis of Word Distribution button and the Keyword System Analysis window will open.
Soundex
The Soundex code is an indexing system which translates words into a 4 digit code consisting of 1 letter and 3 numbers. The most familiar application of Soundex is its use by the US Bureau of the Census to create an index for individuals listed in the US census records after 1880. Soundex only works for characters A through Z and numerals 0 through 9. It ignores any other characters (Unicode non-Latin characters) and the Soundex code becomes the word’s leading character followed by 000, unless there are alphas attached or within the word, for example for the Thai word “จันทร” would be represented by จ000. So the Soundex system is not particularly useful in non-Latin alphabets. Note that in this example the first visible character is in fact a composite-character, so only the first part of the character becomes the leading character of the Soundex code.
The advantage of Soundex is its ability to group names by sound rather than the exact spelling. Take, for example, the name Paine. A census recorder or a family might spell the name variously as Paine, Pain, Pane, Payn, Payne, etc. The Soundex code for all of these is P500.
Soundex Rules are officially as follows, although as you will see Caliach have extended these:
- All Soundex codes have 4 alphanumeric characters [no more, no less]: 1 Letter followed by 3 Digits
- The first Letter of the word is the first character of the Soundex code. (Caliach have extended this to include a number if that is the first character of the word).
- The 3 digits are defined sequentially from the word using the Soundex Key below.
- Adjacent letters in the word which belong to the same Soundex Key code number are assigned a single digit. See examples 2 and 3 below.
- If the end of the word is reached prior to filling 3 digits, zeroes are used to complete the code.
- All codes have only 4 characters, even if the name is long enough to yield more.
|
Key |
For Letters |
|---|---|
|
1 |
B P F V |
|
2 |
C S K G J Q X Z |
|
3 |
D T |
|
4 |
L |
|
5 |
M N |
|
6 |
R |
|
Ignored |
A E H I O U Y W |
Examples
BEADLES = B342
- The first letter of the name is the first part of the soundex code, B
- Vowels are ignored, so ignore EA
- The next part of the code is from the letter D which is assigned 3
- The next part of the code is from the letter L which is assigned 4
- Vowels are ignored, so ignore E and A
- The next part of the code is from the letter S which is assigned 2
- The resulting soundex code for BEADLES is B342
CALLAHAN = C450
- The first letter of the name is the first part of the soundex code, C
- Vowels are ignored, so ignore A
- The next part of the code is from the letter L which is assigned 4
- Two adjacent key letters are coded as one, so the second L is ignored.
- Vowels and Hs are ignored, so ignore AHA
- The next part of the code is from the letter N which is assigned 5
- 3 numbers are required, but we are out of letters, so use 0
- The resulting soundex code for CALLAHAN is C450
SCHULTZ = S432
- The first letter of the name is the first part of the soundex code, S
- Since C is in the same category as the S preceding it, ignore C.
- Vowels and Hs are ignored, so ignore HU
- The next part of the code is from the letter L which is assigned 4
- The next part of the code is from the letter T which is assigned 3
- The next part of the code is from the letter Z which is assigned 2
- The resulting soundex code for SCHULTZ is S432
If the Soundex system is turned on in Caliach, every word extracted is Soundex coded and recorded with an index. If the ?? soundex find syntax is used, the subsequent word entered is converted to a Soundex code and all words with the same code are listed to the user with the appropriate references.
Soundex was particularly designed for names contained in large databases so Caliach has extended it to make it more useful under Caliach Vision circumstances:
- The leading character of a Soundex code can be a number 0 through 9. This enables part numbers and other numeric codes to be included and sensibly located. Without this 123CRST48 would code to C623. When finding it, 123CRST and 799CRST would find the same set of words; it would be very undiscriminating. With Caliach’s Soundex coding 123CRST48 would code to 1623, making the system much more sensitive. NOTE: This only has any effect when you define words as starting with numeric characters. I.E. the Ignore Word List starts with 00 or 0A.
- Numerals 0 through 9 are treated in the same way as vowels and are ignored except where they exist as the first character of the word.
- The Soundex Precision field in the Keyword System Settings window enables you to set the extent of Soundex coding for a word. It is normally set to 4 and in this state the prefix character and all three numeric codes are calculated. If set to 2 or 3, only 1 or 2 numeric codes are calculated. This desensitises the Soundex codes so that a wider range of words are returned to the user. WARNING: The bigger the word file the more sensitive you should set the Soundex precision. If you reduce the precision too far you will get an excessive number of words returned, making things slow and indiscriminate.
![]() CUSTOM CAPABILITY: You can encode your own Soundex codes. String s0904 holds a code character set which you can change using the File — Advanced — String Maintenance. The standard code is:
CUSTOM CAPABILITY: You can encode your own Soundex codes. String s0904 holds a code character set which you can change using the File — Advanced — String Maintenance. The standard code is:
123456789AEHIOUYW00BPFV000000CSKGJQXZ00DT00000000L000000000MN00000000R000000000
They are grouped as follows:
123456789 returns 0
AEHIOUYW00 returns 0
BPFV000000 returns 1
CSKGJQXZ00 returns 2
DT00000000 returns 3
L000000000 returns 4
MN00000000 returns 5
R000000000 returns 6
The string is used to code the characters of a word by locating the first position of the character in the string (e.g. T is in position 41). The integer of this position divided by 10 less 1 is the code (e.g. T, with position 41, codes to integer of 4.1 minus 1 = 3. By changing the characters around you can invent your own Soundex code system!
Keyword Data Structure
The Keyword file (KWDFILE) contains the following data:
|
Field |
Contents |
|---|---|
|
KWDTYPE |
Reference type (1=Part, 2=Customer, 3=Supplier, 4=G/L account, 5=Purchase Part, 6=Customer Part, 7=Serial Numbers, 8=Engineering data, 9=Marketing) |
|
KWDITEM |
Part number, Customer etc primary id |
|
KWDWORD |
Key Word |
|
KWDSOUN |
Soundex of key word |
|
KWDCOLS |
Comma delimited list of columns containing the word |
|
KWDADRC (from V3.1009 onward) |
Comma separated list of links to Addresses and Contacts in the form of con(‘A’,ADRID,’C’,ADCID…..) |
| See also: – |
Compiled in Program Version 5.10. Help data last modified 4 Jun 2012 04:47:00.00. Class wMcdKwd last modified 18 Feb 2015 01:54:44.
![]() Reference Contents > Advanced Functions > Keyword System Settings
Reference Contents > Advanced Functions > Keyword System Settings