Data View Maintenance
![]() Reference Contents > Data Views > Data View Maintenance
Reference Contents > Data Views > Data View Maintenance
A full introduction to Data Views can be found in the Introduction to Data Views topic.
This window is where a design of a Data View is constructed. It is controlled in turn by the Data Views Tools window toolbar.
There are two drop-down lists above the tab pane in which you can select already created Data Views.
A Data View elsewhere is specifically identified by it’s name. The classification is used to group data view designs into sensible groupings.
When saved the design is saved in the database in the XMLFILE, in which Graph 2 designs are also saved. All the details are in fact stored in an XML structure which can be viewed by any XML viewer or on a web browser.
|
Field |
Description |
|---|---|
|
Classifications droplist |
A list of Classifications. Select to build a list of Data Views. |
|
Names droplist |
A list of Data Views for the selected Classification. Select to maintain. |

The window has 5 tab panes.
Data View Basics
Result Columns
SQL Searches
Tables + Joins
Advanced
Data View Basics
The basic definitions for the data view.
|
Field |
Description |
|---|---|
|
Classification |
The data view classification which is used to group data views. For example Parts, Customers, Sales, etc. |
|
Name |
The data view name which is used to identify the generated list of data for the use in a review, report or graph. |
|
Description |
A general purpose description for the data view. |
|
Design notes |
Design notes and history. |
|
Thumbnail |
Thumbnail picture of view. |
|
User access |
User access (comma-delimited list of users IDs that have access) |
|
Group access |
Group access (comma-delimited list of groups that have access) |
|
Main table droplist |
The primary search main table. This determins which, if any, search interface or user search can be used. |
|
Search interface |
The class name and parameters of the subwindow that will provide the user interface for data collection. This will be automatically selected, if available, after choosing the primary search main table. When the Data View is run the Data View Data Selection window will open and provide the user with primary record selection control. If you have a User Interface entered, that is the mechanism of data aquisition that will be ued. All others will be ignored. The following are available:
|
|
User search |
Optionally the name of a user custom search for the primary search main table. If you have no User Interface entered and a User Search entered, the user search will be the mechanism of data aquisition that will be ued. Others will be ignored. |
|
User instructions |
Any user instructions or help that will be shown above the search interface, whether or not you are using one. |
|
Button |
Action |
|---|---|
|
Custom Search |
Click to select an available custom search or design your own special custom search. |
Result Columns
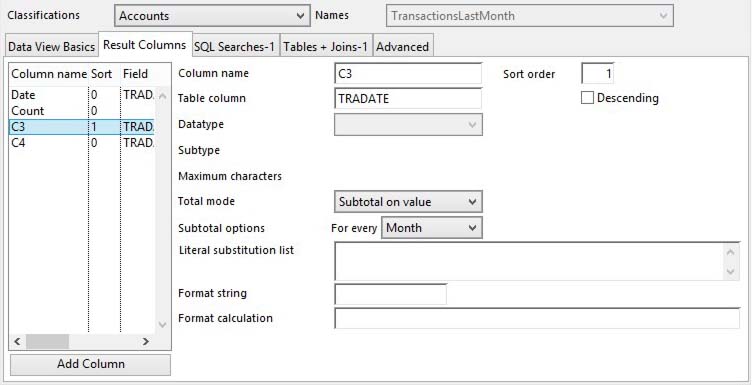
The result set is a matrix list of data. The column data definitions are made here.
|
Field |
Description |
|---|---|
|
Columns list |
List of data groups for the data view. Use the delete key to remove a group. You must have at least one group. |
|
Column name |
The name of the result list column. |
|
Sort order |
A sort order for this column when the list is sorted after any subtotalling. Up to nine columns can be used for the list sorting. Sorting takes place after any literal substitution but before any formatting. |
|
Table column |
If entered this must be a table that will be used in the data aquisition. |
|
Descending |
Check for for a descending order sort. |
|
Datatype |
Select from the dropdown list of field types. The subtype list will be reset depending on your selection. |
|
Subtype |
Select from the dropdown list of data subtypes. The subtype list will be reset depending on your selection of datatype. |
|
Maximum characters |
The maximum length of character fields. |
|
Total mode |
Select from the dropdown list of totalling modes for the group. |
|
Subtotal options interval |
The column subtotal interval. Number of characters for character fields or integer for numbers. |
|
Subtotal options interval start |
The column subtotal interval start for number datatypes. |
|
Date subtotal droplist |
Select from the dropdown list of date subtotal options. |
|
Literal substitution list |
Comma separated list of values and their substituted text, in pairs. |
|
Format string |
Optional column data formatting string as used in a jst() function. See help. |
|
Format calculation |
A calculation applied to the column for formatting purposes. #S1 must be used to refer to the column value before being formatted. |
|
Button |
Action |
|---|---|
|
Add Column |
Click to add a further group. |
SQL Searches
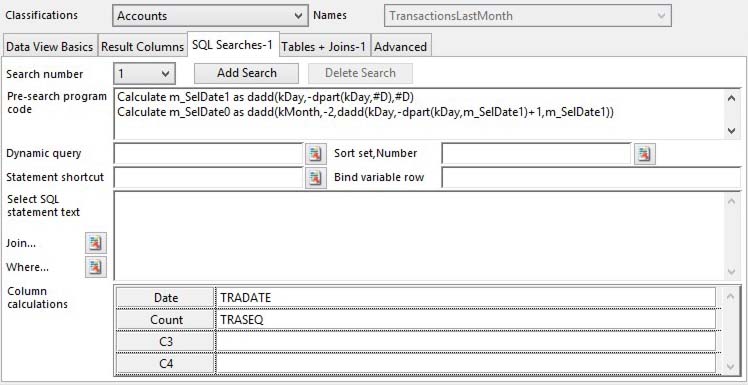
Searches on the data to generate the data for the view.
|
Field |
Description |
|---|---|
|
Search number |
Searches are carried out in sequence. Select to maintain. |
|
Pre-search program code |
Omnis Studio code that will be run before the data collection starts. Optionally used for preparation and setting up constants or otherwise setting values to drive the selection process. |
|
Standard search generator context menu |
Use this menu applies standard pre-search program code and Main table where clause. |
|
Dynamic Query name |
A Dynamic Query is a pre-defined data collection mechanism. Typically all reports that use a selection window use Dynamic Queries. They are stored in the Extras/Statements.db database. If you have no User Interface or User Search entered, the Dynamic Query will be the mechanism of data aquisition that will be ued. Others will be ignored. Click on the button beside the field to choose from a list. |
|
Sort Set,Number |
With a Dynamic Query the order of data returned can be controlled by a named Sort Set, just as typical report selection windows has radio buttons to allow the user to control the order. A sort set name followed by a comma and number will set the Sort Order just like the radio buttons do. For example, A parts report uses Cal_PtmPrint sort set and ,5 will order parts by stores preferred location (first radio buton is value 0). |
|
Statement Shortcut name |
Statement Shortcuts are pre-defined data collection mechanisms of a more targetted nature than Dynamic Queries. They are similarly stored in Statements.db and are generally work for any server engine. They often are much faster than Dynamic Queries as they target a more limited set of data. If you have no User Interface, User Search or Dynamic Query entered, the Statement Shortcut will be the mechanism of data aquisition that will be ued. Others will be ignored. |
|
Bind variable row |
Bind variables are a way of passing variable data into a fixed SQL statement in text. They can be used for Statement Shortcuts, SQL Text and Table and Join mechanism. For example, say you wanted to have a data view of dispatches yesterday. The where clause would need to be: WHERE SAHDDAT='2015-01-10' It would be very tedious to manually have to change the date each day. What we can do to solve this is change to a bind variable which would look like this: WHERE SAHDDAT=@[iRow.C1] and have a Bind variable row of: #D-1~23~0~0 The bind variable is a column of a row variable which in this example is today’s date (#D) minus 1. The syntax used defines the data calculation for one or more columns and it’s type, subtype and sub-length as 4 entries separated by a ~ character. To add more columns repeat, so: #D-1~23~0~0~#D-2~23~1000~0 Will create a two column row with C1 containing yesterdays date and C2 containing tomorrow’s date and time. The permitted types are:
Permitted subtypes are:
|
|
Select SQL statement text |
You can write a raw SQL statement to drive the data collection. The statement must begin with the SELECT keyword and contain a FROM keyword. If you have no User Interface, User Search, Dynamic Query or Statement Shortcut entered, the Select SQL Statement Text will be the mechanism of data aquisition that will be ued. Others will be ignored. The following is an example: SELECT SOLSONO,SOHDATE,SOLPRIC,SOLDISC,SOLSQTY,SOHRATE,SOLCUSC,CUSCNAM,SOHCREF,SOHAREF FROM SOLFILE JOIN SOHFILE ON SOLSONO=SOHSONO JOIN CUSFILE ON SOLCUSC=CUSCODE This will return every quotation and sales order line items. To limit it to Orders you could add a where clause: WHERE SOHRELF You can incorporate predefined Join and Where Shortcuts that will be expanded into the SQL statement before execution. For example the above FROM clause could be replaced by: FROM =[Cal_SolSohCusAdrPtm] Where Shortcuts can be included in the WHERE clause: WHERE =[Cal_SoOnly] AND SOLDATE=[Cal_Yesterday] The above illustrates the two types of Where Shortcuts. The first simply is a subtitution of conditional logic. The second applies a set of logic to a particular column, in this case SOLDATE. The resulting SQL for SQLite will be: WHERE SOHRELF AND SOLDATE>=date('now','localtime','start of day','-1 days') AND SOLDATE<date('now','localtime','start of day')
This will select all Order line items due for delivery yesterday.
SQLite=SELECT datetime('now')
MySQL=SELECT NOW()
PostgreSQL=SELECT current_timestamp
|
|
Column calculations |
A calculation used to generate the value for each result column from the raw results data delivered from the server. |
|
Column name |
The name of the result list column. |
|
Column calculation |
A calculation used internally to generate the value for each graph group member. Delivered columns must be refered to in the form iRow.<ColumnName> where iRow in this case is the list variable line of the results returned from the server. |
|
Button |
Action |
|---|---|
|
Add Search |
Click to add a further search. |
|
Delete Search |
Click to remove the selected search. There must be at least one search. |
|
Select Test |
Click to open the Ad Hoc Database Listing window in which you can try out any SQL statement. |
Tables + Joins
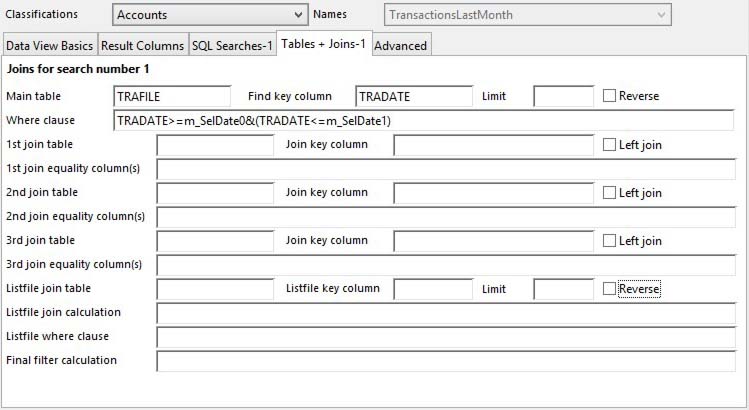
For each search you can define a main table and up to 3 joined and one listing table.
|
Field |
Description |
|---|---|
|
Main table |
The main table to be used for the search. |
|
Find key column |
The column to be used for ordering the data. This is only useful generally if a Limit is being applied (see below). |
|
Limit |
The limit for the main file records collected (<1 for all available records).
|
|
Reverse |
Reverses the order of the resulting returned rows based on the main key column. |
|
Where clause |
You enter here the where clause elements to restrict the rows returned from the server. It is executed on the server so needs to include only functions and syntax that the server can understand. A context menu is available with pre-prepared engine-specific where parts which will load into the field. Many of them involve dates and expect a column to be pre-entered. You enter a column, say SAHDDAT, operate the menu, say Last Week and the Where clause will be expanded and the Pre-search program code. In this case the Pre-seach will be set to: Do $ctask.tSqlData.$CurDate() Returns iD Calculate iRow.m_SelDate1 as dadd(kDay,-(dtw(dadd(kDay,pick(getws()-12,-6,0,-1,-2,-3,-4,-5),iD))-1)-1,iD) Calculate iRow.m_SelDate0 as dadd(kDay,1,dadd(kWeek,-1,iRow.m_SelDate1)) The Where clause will be set to: SAHDDAT>=@[iRow.m_SelDate0] AND SAHDDAT<=@[iRow.m_SelDate1] The iRow here is a universal select row containing all the m_Sel… variables. Their values are set in the Pre-search code and the Where clase uses them in the form of bind variables (surrounded by @[…]). |
|
1st Join table |
The first join table that is related to the main table with the column relationship below. |
|
1st Join key column |
The column in the join table whose value equals the result of the equlity column(s) below. |
|
1st Left Join |
Check for a left join. A left join permits the inclusion of records where the join exact match fails. |
|
1st Join equality column(s) |
A column or combination of columns that when compared to the key column value is an equality when matched. This is executed on the server so if it includes functions they must be executable by the server engine employed. |
|
2nd Join table |
The second join table that is related to the main or first join table with the column relationship below. |
|
2nd Join key column |
The column in the join table whose value equals the result of the equlity column(s) below. |
|
2nd Left Join |
Check for a left join. A left join permits the inclusion of records where the join exact match fails. |
|
2nd Join equality column(s) |
A column or combination of columns that when compared to the key column value is an equality when matched. |
|
3rd Join table |
The third join table that is related to the main or previous join tables with the column relationship below.ow. |
|
3rd Join key column |
The column in the join table whose value equals the result of the equlity column(s) below. |
|
3rd Left Join |
Check for a left join. A left join permits the inclusion of records where the join exact match fails. |
|
3rd Join equality column(s) |
A column or combination of columns that when compared to the key column value is an equality when matched. |
|
Listfile join table |
Optional Listfile table to be linked to the main, and/or joins, table with the join calculation and where clause below. The listfile join will find multiple records for data collection. |
|
Listfile key column |
The column in the listfile table column whose value equals the result of the calculation below. Data is collected in the key column order with respect to any Limit and Reverse. |
|
Limit |
The limit for the number of listfile records collected (<1 for all available records).
|
|
Reverse |
Reverse find from the last then previous down the Listfile key index. |
|
Listfile join calculation |
A calculation, evaluated intermally, the resulting value of which is used to locate the appropriate listfile file records. It must be an Omnis calculation that references the columns returned by the Main and/or Join tables using iRow.<ColumnName> syntax. For example: con('''',iRow.SOHSONO,'''')
con('''',dat(iRow.SOHDATE,'y-M-D'),'''')
When evaluated this forms the initial where clause part for the Listfile select, which is ANDed to the Listfile Where clause, if entered. |
|
Listfile where clause |
An optional where clause applied to the listfile select. |
|
Final filter calculation |
An optional final search calculation applied to the data of all tables prior to adding Listfile to the further filter results. It should return true to include the record result using iRow.<ColumnName> syntax. This is executed internally and so must be Omnis code. |
Advanced
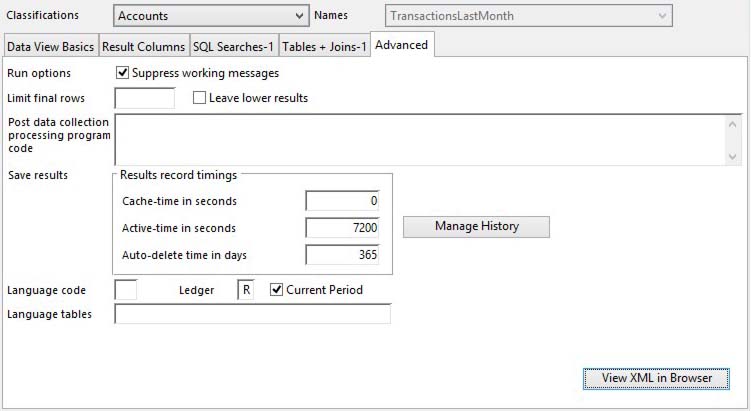
Advanced options for the handing of the resulting data list.
|
Field |
Description |
|---|---|
|
Suppress working messages |
Check for to suppress the normal working message during data collection. |
|
Limit final rows |
Truncates the final results to a limited number of rows of consolidated and sorted data (<1 for no truncation of results).
|
|
Leave lower results |
Truncatation of the upper portion rather than the lower portion of the sorted final results. |
|
Post data collection processing program code |
Omnis Studio code that will be run at the end of data collection. The results are in a local list variable named pList.
Do $ctask.tPrint.$InvertDataList(pList) |
|
Cache-time in seconds |
Cache-seconds for which the last data collection set remains used (cached) after which data will be rebuilt (<1 = never saved). |
|
Active-time in seconds |
Active-seconds after cache period for which the last data collection set will be rebuilt after which a new record of the data is created (<1 = perpetually rebuilt, single record). |
|
Auto-delete time in days |
Delete-days after which the data record is automatically deleted (<1 = never deleted automatically). |
|
Language code |
Language code for the data collection that, if set, overrides the Language Swap choice at the time of collecting . |
|
Ledger |
The ledger (R, P or G) relevant to the data collection to determine which ledger period applies to the data (will set DAVPERN). |
|
Current Period |
Check when the current ledger period is applied rather than the preceding closed period. |
|
Button |
Action |
|---|---|
|
Manage History |
Click to manage cache and history records of data collection by this Data View. |
|
View XML in Browser |
Click to view the underlying design in XML in your Browser. This will work only if your Browser is the default program for .xml files. It creates a temporary file in the Email/Temp folder. |
| See also: – |
Compiled in Program Version 5.10. Help data last modified 21 Jan 2017 10:21:00.00. Class wDataViewMaint last modified 23 Sep 2017 10:50:51.
![]() Reference Contents > Data Views > Data View Maintenance
Reference Contents > Data Views > Data View Maintenance